

Deploying Mendix apps in Kubernetes can be more complex than anticipated, often leading to potential issues like data corruption. This article delves into the specific challenges of running Mendix apps in a cloud-native environment. It examines the risks posed by concurrent versions, the importance of the leader-workers model, and the impact of deployment strategies. Furthermore, it explores the introduction of Mendix for private cloud and the mitigation techniques that can be employed to ensure a smooth and secure deployment process. By implementing the suggested strategies, developers can minimize the risk of data corruption and streamline the operation of Mendix apps in Kubernetes environments.
No blue-green with Mendix app
Mendix apps are cloud native. To be specific, there is a nuance to Concurrency; factor 8 from the 12 factors framework. With Mendix, horizontal scaling is achieved using the leader-workers model.
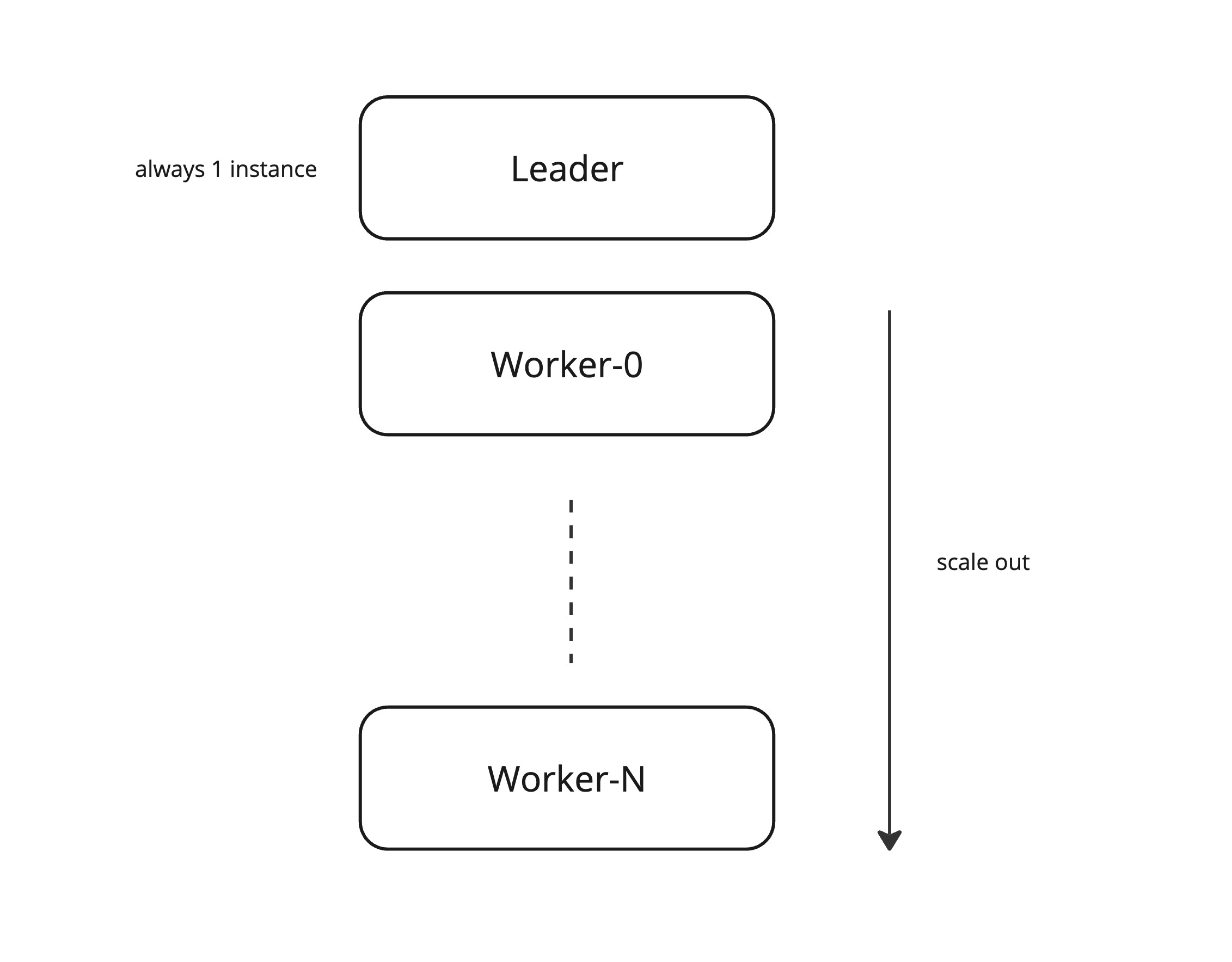
There can be only 1 leader of the app active at any point in time. The leader is responsible for updating the database schema so that it is compatible with the active model version. Depending on the changes between the old and new model, sometimes this updating process can take a long time when more complicated actions are needed like converting one attribute(column in the database) from one type to another.
Therefore your users could be using an old model against a newer database schema and data if we would allow both versions to be active concurrently. That could pose a big risk resulting in undefined behavior.
Besides the multi-model issue there is also a potentially higher risk: if the window of which two leader pods are active is longer than a few minutes, it’s possible a scheduled event is fired multiple times. If the developer did not anticipate that (most don’t), it can cause data corruption internally or externally if not handled correctly.
Custom private cloud with docker-mendix-buildpack
In the early days of running Mendix apps in Kubernetes you have most probably used the docker-mendix-buildpack. This method is most flexible where you package your Mendix app runtime into a single self-contained OCI image. This image is just like any other images and can be deployed into Kubernetes using, in most cases, a Deployment resource.
For scalability, it is advised to create two deployments instead to implement the leader-workers model. Most deployments overlook a tiny detail that will in practice allow multiple leader pods to co-exist for a few minutes. This detail is the deployment strategy which by default has the value RollingUpdate. This means during a Deployment update the old pod is kept alive until the new pod is in ready state. Regular cloud native apps often account for the RollingUpdate behaviour.
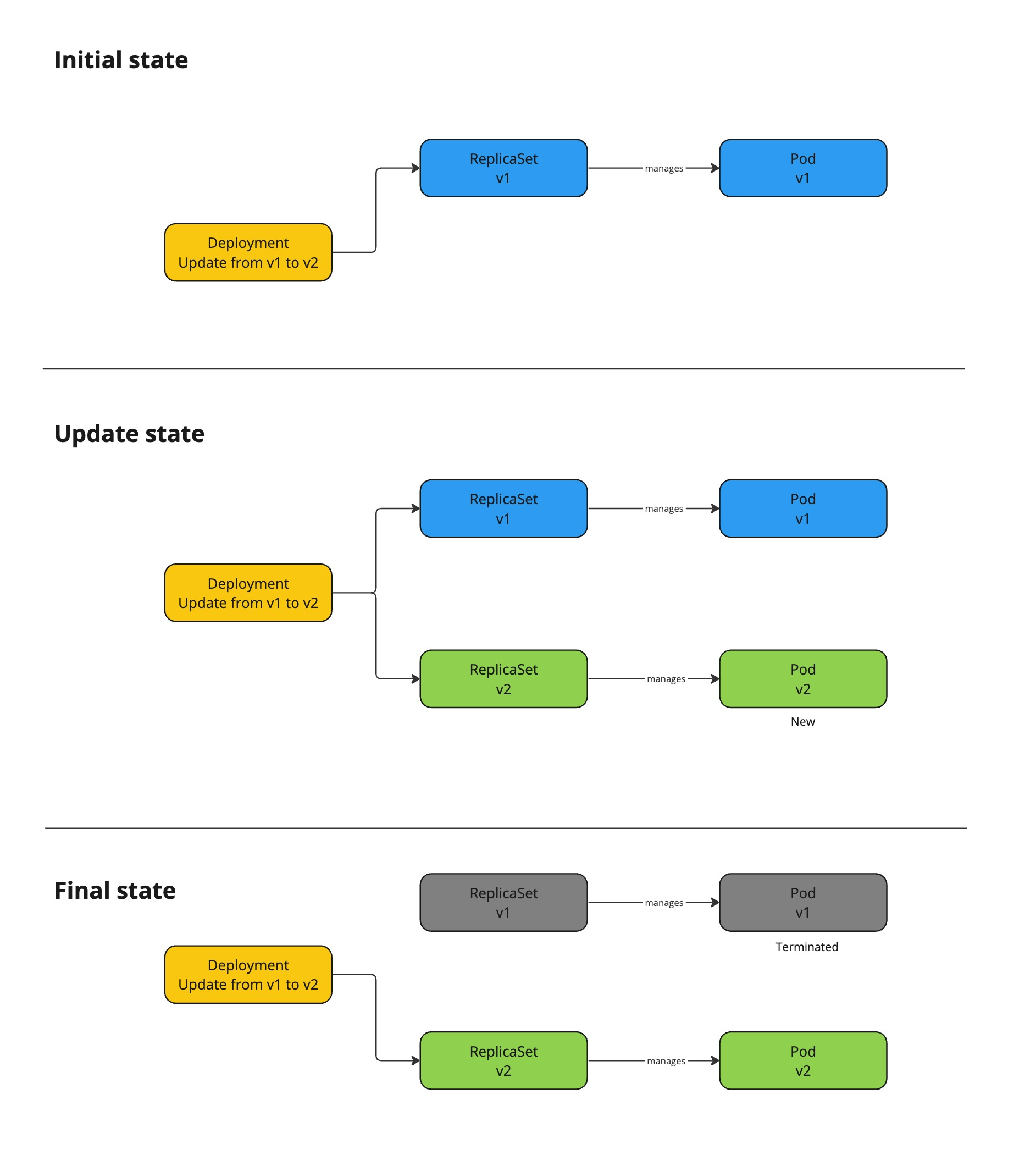
Do note that this issue is not strictly limited to Mendix apps. However, Mendix apps are more susceptible to data corruption because Mendix developers often do not consider this scenario neither does the internal db schema update system.
Mendix for private cloud
In recent years there is a product offering called Mendix for private cloud. It simplifies Mendix app deployment by introducing a new Custom Resource Definition called MendixApp. In here you describe the deployment specification in which the Mendix operator will read as input. It manages kubernetes resources like Secrets and Deployments where it abstracts away some of the complexities of operating Mendix apps.

Similar to the custom approach it implements the leader-workers method. The Mendix operator has addressed this edge case. We will show how in the mitigation section below.

Demo: problem
When RollingUpdate is used, there’s a window of which 2 leader pods are active at the same time. In the video above we re-purposed a Mendix for private cloud managed deployment to show the issue of RollingUpdate.
Mitigation
Due to the leader-worker model it is difficult to have a single solution that works in all possible scenarios. However, we still have a simple solution:
The leader deployment must have deployment strategy Recreate. This means that when the deployment is updated due to model version change or restarted due to node upgrades, the old pod is first terminated before the new pod is created. Mendix operator (verified in version ) has this already implemented.
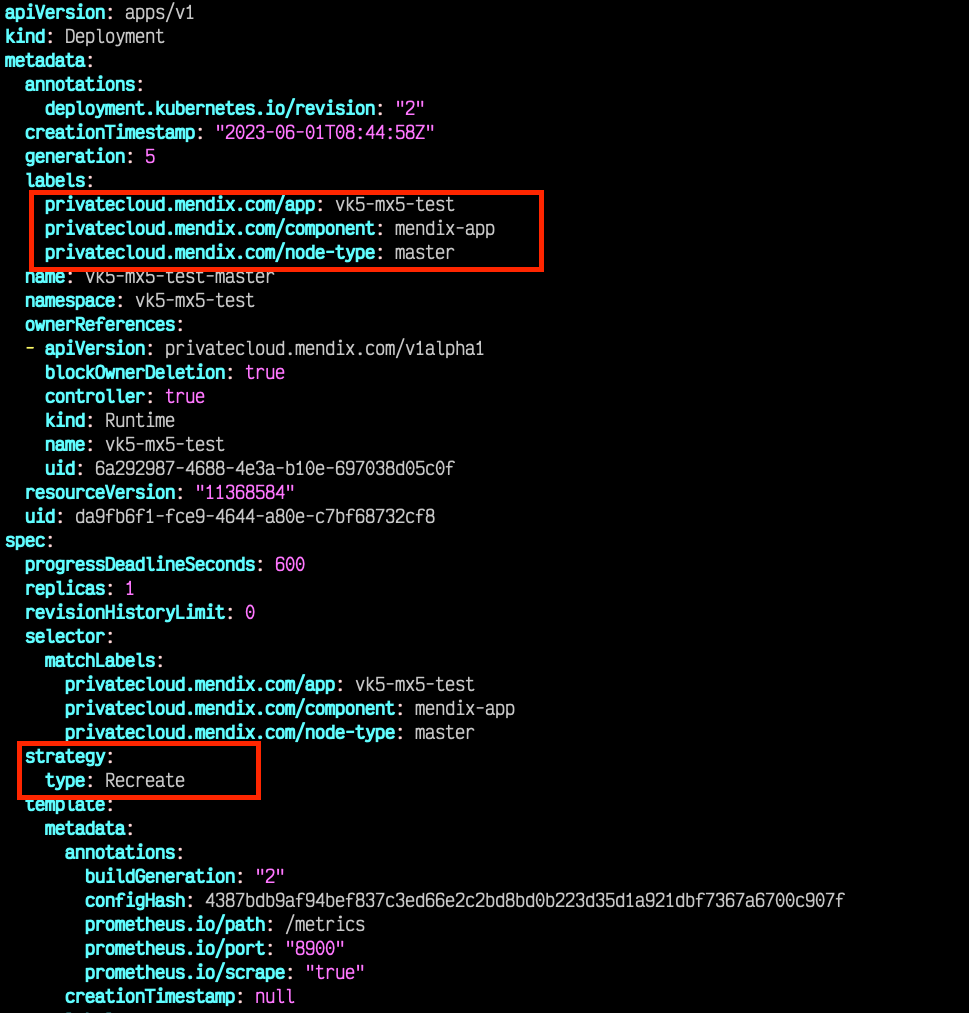
This solves the problem of accidentally having two leaders active at the same time by leveraging the internal capabilities of Kubernetes deployment controller.
With the above, we have mitigated the problem for the leader deployment. What about the workers? During maintenance, there is no issue because workers can be scaled up and down as needed. Therefore the default RollingUpdate is fine and desirable.
You might ask: what about a new model version update? You must handle this common scenario during deployment; often in your pipeline:
- scale down the worker deployment replicas to zero. This stops all worker pods. Alternatively you can also remove the worker deployment all-together if desired. As long as all worker pods are terminated. For safety reasons you should wait until all pods are terminated before proceeding with next step
- Update the leader deployment with new model version. In practice it’s better to wait because sometimes the leader pod may fail to start. In that case it’s best to fail the whole pipeline and remediate the issue.
- Update (or create if previously removed) the worker deployment with the new model version and the desired number of replicas. New worker pods block until the leader has started successfully.
That’s it. With the above strategy, we have minimized the risk of data corruption by ensuring the leader pod is always running once. With this approach we are also safe from potential data corruption during a cluster maintenance when pods are restarted according to their parent Deployment strategy.
Demo
Here we see the old pod is first terminated before the new version is instantiated in the Recreate mode. This way there’s only 1 version active at any point in time.
Summary
Deploying Mendix apps in Kubernetes is harder than most think. Edge cases, that could cause silent data corruption, are just around the corner.
Today you have learned some of these edge cases and how to mitigate them successfully using proper Deployment strategy at both Kubernetes and pipeline level.
Low-Ops platform implements these best practices straight out of the box so that you don’t have to.